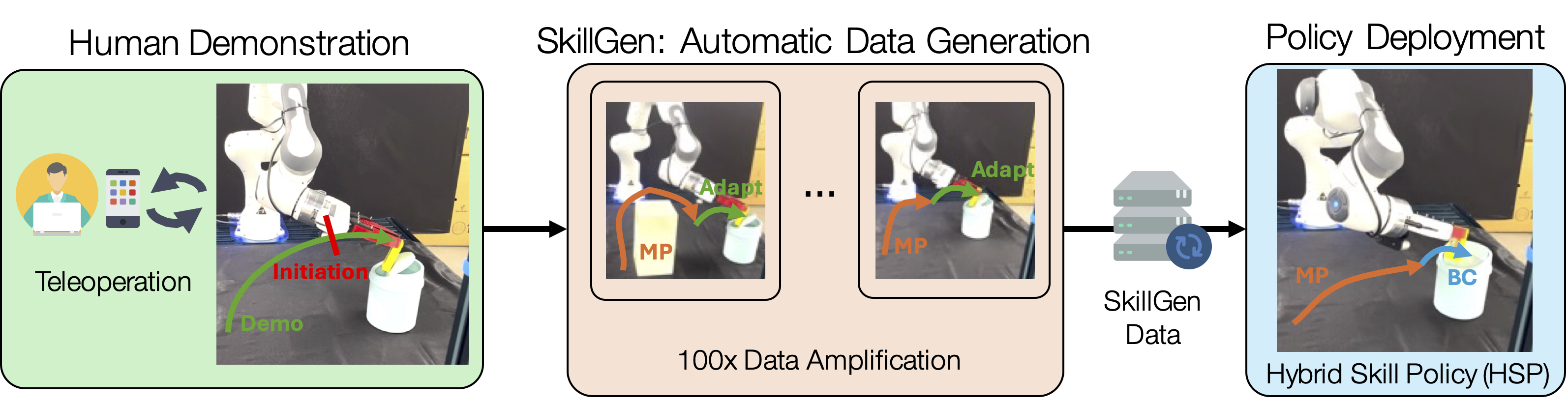
First, a human teleoperator first collects ~3 demonstrations of the task and annotates the start and end of the skill segments, where each object interaction happens. Then, SkillGen automatically adapts these local skill demonstrations to new scenes and connects them through motion planning to generate more demonstrations. These demonstrations are used to train Hybrid Skill Policies (HSP), agents that alternate between closed-loop reactive skills and coarse transit motions carried out by motion planning.
SkillGen integrates learned policies and planning to solve real-world manipulation tasks with just 3 human demonstrations
SkillGen was used to generate 100 demonstrations automatically from just 3 human demonstrations. An HSP-Class agent was trained on the data and achieves 95% success rate on the Cleanup-Butter-Trash task.
SkillGen outperforms a state-of-the-art data generation system. It also achieves comparable performance to state-of-the-art imitation learning with 3% of the human data and fewer assumptions
On the challenging Coffee task, real-world SkillGen policies outperform those trained on MimicGen (a SOTA data generation system) data (65% vs. 14%). It achieves comparable results to HITL-TAMP (a SOTA imitation learning method achieving 74%) while using just 3% of the human data and making fewer assumptions.
SkillGen enables trained agents to be robust to large pose variation
An agent trained on SkillGen data achieves 95% success rate on the Pick-Place-Milk task, over a wide range of milk and bin placements.
SkillGen enables zero-shot sim-to-real transfer with 1 human demonstration provided in simulation
The SkillGen simulation policy achieves 35% success rate on the challenging Nut Assembly task in the real world.
The single human demonstration used for SkillGen.
1000 generated SkillGen demonstrations.
SkillGen agent evaluated in simulation.
SkillGen can generate data in cluttered workspaces
SkillGen can generate data even when large obstacles that were unseen in the human-provided source demonstrations are present.
Pick-Place-Bin
Cleanup-Butter-Trash
SkillGen data can produce near-perfect agents across a wide variety of tasks
We train Hybrid Skill Policies (HSP) on SkillGen datasets. These agents learn skill initiation conditions, closed-loop skill policies, and skill termination conditions. The skills (red border) are sequenced via motion planning (blue border).
Square D2 (94%)
Coffee D2 (100%)
Piece Assembly D2 (84%)
Threading D1 (84%)
Nut Assembly D1 (78%)
Coffee Prep D2 (84%)
Agents trained on SkillGen demonstrations can be comparable to agents trained on comparable amounts of human data
We generate 200 SkillGen demonstrations from 10 human demonstrations and compare trained agent performance with using 200 human demonstrations. Results are similar, but SkillGen requires a small fraction of the human effort.
Using 200 SkillGen demos generated from 10 human demos results in 36% success on Threading D1.
Using 200 human demos results in 32% success on Threading D1.
Generating larger SkillGen datasets is an easy way to boost performance without human effort -- agents demonstrate strong improvement with larger SkillGen datasets
We compare agent performance on 200, 1000, and 5000 SkillGen demos. Agents can improve substantially when using more generated data -- Threading D1 improves from 36% to 84% and Square D2 improves from 4% to 72%.
Threading D1, 200 demos, HSP-TAMP (36%)
Threading D1, 1000 demos, HSP-TAMP (72%)
Threading D1, 5000 demos, HSP-TAMP (84%)
Square D2, 200 demos, HSP-Reg (4%)
Square D2, 1000 demos, HSP-Reg (52%)
Square D2, 5000 demos, HSP-Reg (72%)
SkillGen can generate demos for different robots
Using SkillGen, we use 10 human demos on a Panda robot for each task to produce 1000 demos on a Sawyer robot.
Square D1 (Sawyer)
Threading D1 (Sawyer)
Nut Assembly D1 (Sawyer)
Tasks
We visualize SkillGen dataset trajectories for each task below. The red border indicates a skill segment.
Square D0
Square D1
Square D2
Threading D0
Threading D1
Threading D2
Piece Assembly D0
Piece Assembly D1
Piece Assembly D2
Coffee D0
Coffee D1
Coffee D2
Nut Assembly D0
Nut Assembly D1
Nut Assembly D2
Coffee Prep D0
Coffee Prep D1
Coffee Prep D2
Square D1 (Clutter)
Square D2 (Clutter)
Coffee D0 (Clutter)
Coffee D1 (Clutter)
Pick-Place-Milk
Cleanup-Butter-Trash
Coffee
Task Reset Distributions
We visualize the reset distribution for each task variant below.
Square D0
Square D1
Square D2
Threading D0
Threading D1
Threading D2
Piece Assembly D0
Piece Assembly D1
Piece Assembly D2
Coffee D0
Coffee D1
Coffee D2
Nut Assembly D0
Nut Assembly D1
Nut Assembly D2
Coffee Prep D0
Coffee Prep D1
Coffee Prep D2
Square D1 (Clutter)
Square D2 (Clutter)
Coffee D0 (Clutter)
Coffee D1 (Clutter)
Pick-Place-Milk
Cleanup-Butter-Trash
Coffee
SkillMimicGen (SkillGen) Supplemental Video
BibTeX
@inproceedings{garrett2024skillmimicgen,
title={SkillMimicGen: Automated Demonstration Generation for Efficient Skill Learning and Deployment},
author={Garrett, Caelan and Mandlekar, Ajay and Wen, Bowen and Fox, Dieter},
booktitle={8th Annual Conference on Robot Learning},
year={2024}
}Acknowledgements
This work was made possible due to the help and support of Yashraj Narang (assistance with CAD asset design and helpful discussions), Michael Silverman, Kenneth MacLean, and Sandeep Desai (robot hardware design and support), Ravinder Singh (IT support), and Abhishek Joshi and Yuqi Xie (assistance with Omniverse rendering).